{kind=link}
Saturday, December 3rd, 2016
Introducing Intellectual Encounters, Escaping Errors of Classification, and Why LWP Is Not an Archive
In 2016, the Linked Women Pedagogues work team engaged eighteen** Rhetoric and Composition scholars from across the country in a three-phased research protocol. We sought their preconceptions and perceptions about the project through recorded interviews, in asynchronous wireframe sessions, and from their responses on a series of participatory design tasks. Their participation yielded rich and varied results, enabling us to understand how to solidify our desires and where to clarify our goals. If any one theme emerged throughout the different phases of this protocol, it was the tension between wanting the LWP to embody archival construction and appreciating LWP’s deconstructionist potential.
Introducing LWP as “not-an-archive” may seem odd, but this negation is the most accurate way to describe its principal qualities and functions. Ideally for humanities researchers, digitally networked traces of activity such as LWP are useful because they offer more than a historical representation of events; ideally, they serve the function of “performative idiom[s]” (Pickering, The Mangle of Practice, 147), helping researchers to re-balance their understanding of science’s material powers (Pickering, 7), and enabling them to question the presumed discreteness between the material and immaterial, the human and the non-human in an actor-network (Pickering, 11). Within the context of rhetoric and writing studies, these performative idioms demonstrate the need to materialize inferences, references, and archival activity that occurs in the margins.
For example, between 2009 and 2010, Patricia Sullivan and I populated a spreadsheet called “New Old Texts,” building on Sullivan’s decades-long effort to collect, catalogue, and study nineteenth- and early twentieth-century rhetoric or writing primers in print or digitized forms. More specifically, we recorded via spreadsheet (1) how many of these primers were authored or co-authored by women; (2) when they were published; (3) where they could be found (if already digitized); (4) how they might be classified (e.g., as rhetorics, readers, grammars, business writing texts, secondary-school texts, etc.); and (5) where else they might be referenced in macrohistories of the field.
While there is much we do not know about the actual or presumed value of these primers, the “New Old Texts” exercise points to a cache of teachers, mentors, and administrators whose careers are reflected in interstitial metadata more systematically (and perhaps more reliably) than in bibliometric data. For some of them, their archives are robust; for others, their institutional memories occur outside of the disciplinary mainstream. Due to the nature of their work, the focus of their scholarship, or their institutional stature, transience or mobility, most of them escaped the purview of a particular collection or archive. These escapes are what LWP seeks to demonstrate through the recreation of various intellectual encounters. Ultimately, we assume that such encounters have historiographic value for what they reveal about historians’ uses of data.
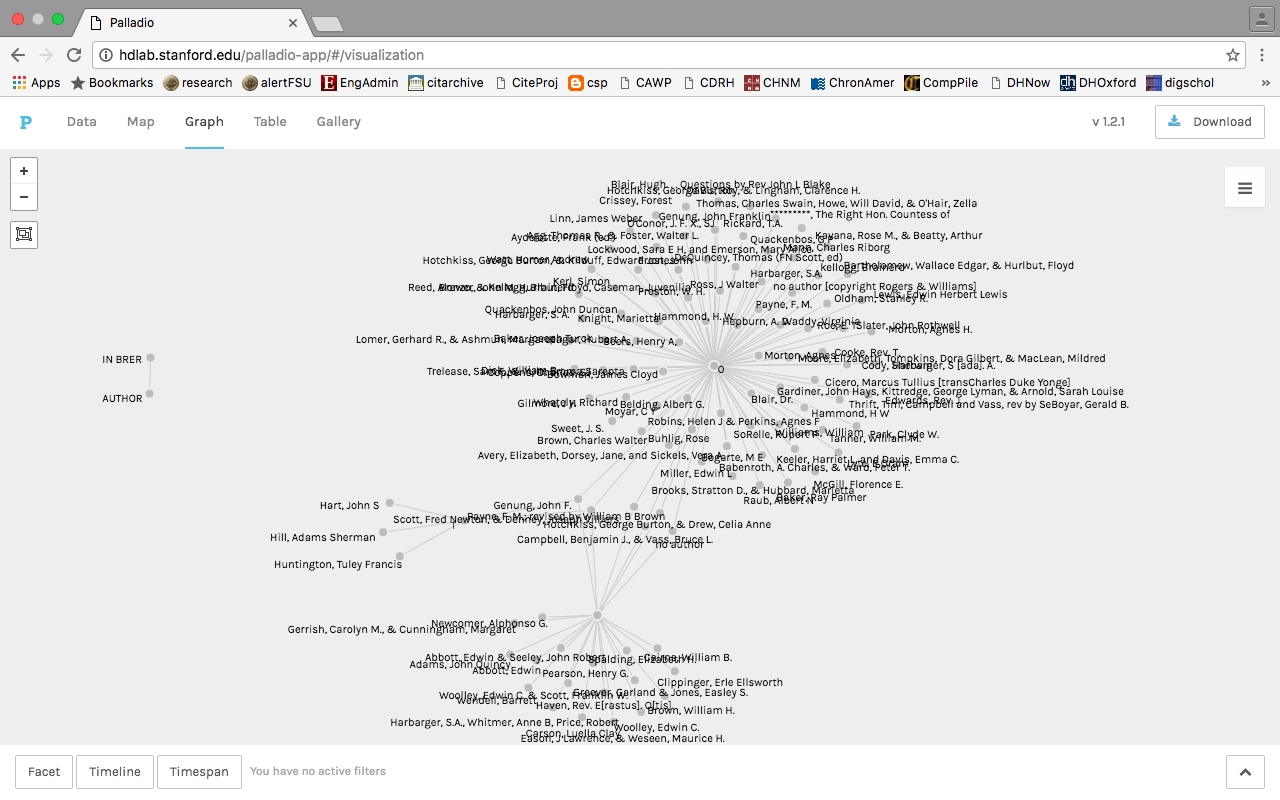
An intellectual encounter is not an abstraction; it is a concrete demonstration of how a researcher identifies, tries to resolve, or fails to resolve a data-driven historical problem. As such, it has potential for digital epistemology. Earlier this year I returned to “New Old Texts,” converting two pages of the original spreadsheet into csv files so that they would be ready for visualization in Palladio and Gephi, and so as to revisit our historiographic assumptions from 2009. The first visualization (Fig. 1) compares the concentration of authors whose primers are or are not explicitly mentioned in John Brereton’s The Origins of Composition Studies in the American College, 1875-1925.

Fig. 1 – Palladio visualization comparing concentrations of authors from Sullivan’s “New Old Texts”
to their frequency in Brereton’s macro history
Here, the “1” value means that authors do appear in Brereton’s history with the designation of “rhetoric,” while the “0” value means they do not appear anywhere in his text, and those clustering around no value are as yet undetermined (i.e., they might appear in Brereton’s history, but under a different designation). Most names on the spreadsheet cluster around “0,” given that they reflect an extra-bibliographic corpus, found or browsed or stumbled upon in various references in various print and online sources; notably, however, most women’s names cluster around no value, i.e., appear as undetermined designations.
The second visualization (Fig. 2) compares the concentration of texts authored by women and historicized by Albert Kitzhaber’s Rhetoric in American Colleges, 1850-1900.

Fig. 2 – Palladio visualization comparing concentrations of textbooks from Sullivan’s “New Old Texts”
to those historicized in Kitzhaber’s macro history
Here, the “1” value signifies titles that are designated as “rhetoric” in Kitzhaber’s history, while the “0” value signifies titles that are designated in other ways. Most titles still cluster around “0” but for markedly different reasons than in Figure 1 above.
Neither visualization provides more information than the original spreadsheet, yet each one suggests the need to question the historical biases that bear on how texts, curricula, and programmatic archives are designated or classified. In the process, I realized several things concretely.
First, it would be easier to visually represent co-authors if they occupied their own row in the spreadsheet, and hence if they could serve as their own data point on the visualization. Second, to render a more meaningful visualization with these particular programs, one would have to structure the csv file according to location and time, rather than by author and genre. Third, the filter restrictions on simple tools like Palladio and Gephi do not allow for more than three discrete factors to be visualized as a relationship; the only way around this dilemma is to ensure that each row or data point in the csv file already reflects a relationship between two or more facets—for example, the relationship between women-authored “grammars” referenced in Kitzhaber’s history vs. those referenced in Brereton’s history; or the relationship between “rhetorics” that are searchable online versus only found in brick-and-mortar archives. Finally, my visualizations added few new perspectives to our search, given that the implicit relationships we sought to discover between and about women authors were already visible in the spreadsheet itself. However, if a single reference on a spreadsheet can generate methodological questions about what kinds of data to gather in order to derive a useful visualization, then that same reference may elicit a more vital set of concerns.
Ultimately, my response to this Encounter is to admit the limited value of most visualizations for interrogating bibliometric inclusions and exclusions in historical work, and to ask why they are so limited: Are these limitations idiosyncratic or disciplinary, contextual or methodological? What kinds of research processes do they help to inform even as they fail to spatially represent new knowledge? Why do so few of these texts get classified as “rhetorics,” when their titles or chapter arrangements support that classification (or vice-versa, extending the same question to composition books and technical writing primers whose classifications in Kitzhaber’s or Brereton’s histories differ from “New Old Texts”)? Consequently, we might ask what other questions could be raised about how historical bias, institutional accessibility, and patterns of circulation make women authors more or less visible within certain classifications: Whose classification errors might they be? What kind of data sets must we create in order to look beyond them?
-T. Graban
**The LWP Project team is indebted to the following individuals: Katherine Adams, James Beasley, Suzanne Bordelon, Ana Cooke, Wendy Hayden, Lynee Lewis Gaillet, Carol Mattingly, Jenna Morton-Aiken, Derek Mueller, Courtney Rivard, Kathleen J. Ryan, Nathan Sheply, Ryan Skinnell, Carolyn Skinner, Kevin Smith, Janine Solberg, Jeremy Tirrell, and 1 anonymous participant.